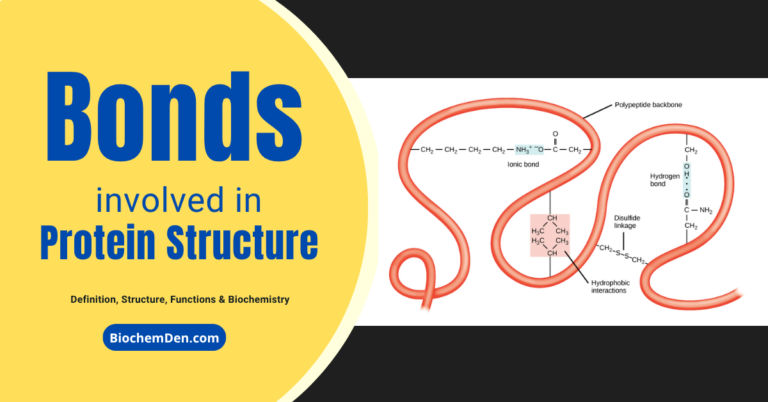
Primary Structure of Proteins: Definition, Examples & Importance
Did you know that changing just one amino acid out of hundreds in a protein can cause a life-threatening disease? That is exactly what happens in sickle cell anemia — a single amino acid substitution in the hemoglobin protein transforms normal, round blood cells into rigid, sickle-shaped ones that block blood flow.
This is the extraordinary power of the primary structure of proteins.
Proteins are the workhorses of every living cell. They build your muscles, speed up chemical reactions, fight infections, carry oxygen, and regulate nearly every biological process in your body. But here is the key question: what makes each protein unique? The answer lies in its primary structure.
Proteins are not just random chains of molecules. They are organized into four distinct levels of structure—primary, secondary, tertiary, and quaternary. Each level builds on the one before it, like floors of a building. And the primary structure is the foundation — without it, nothing else can exist.
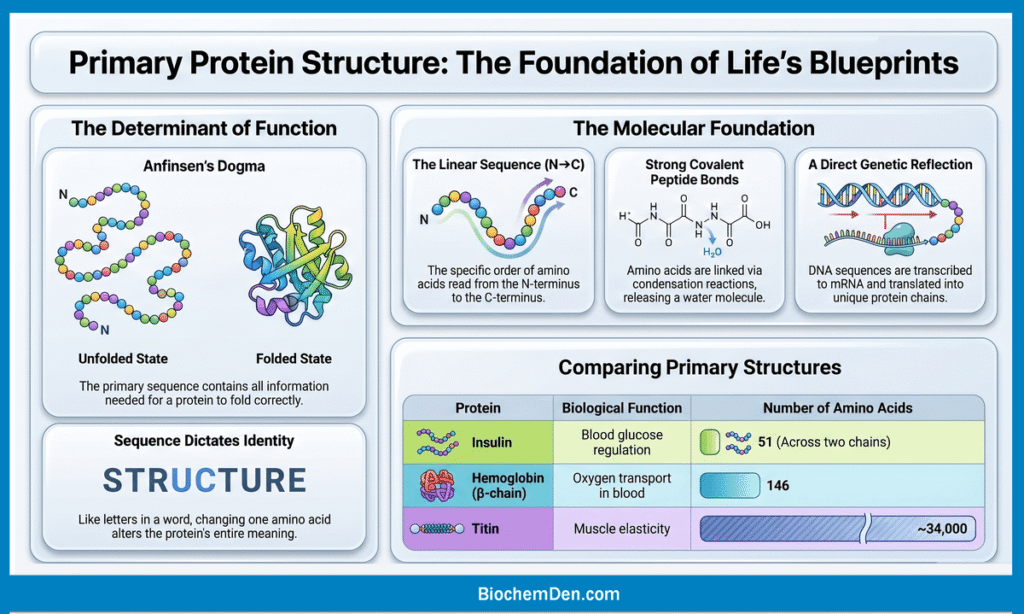
📌 Definition: The primary structure of a protein is the unique, linear sequence of amino acids in a polypeptide chain, covalently joined by peptide bonds, and read from the N-terminus (–NH₂) to the C-terminus (–COOH).
This sequence is not random — it is precisely determined by the DNA sequence of the corresponding gene. Every protein in your body has a specific amino acid sequence, and that sequence dictates how the protein folds, what shape it takes, and ultimately, what function it performs.
In this article, you will learn:
- What the primary structure of proteins is and how it is defined
- How peptide bonds form between amino acids
- The key characteristics that define primary structure
- Real-life examples like insulin and hemoglobin
- Why even a tiny change in primary structure can cause disease
- How scientists determine the primary structure of a protein
- How primary structure compares to secondary, tertiary, and quaternary structures
Whether you are a biology or biochemistry student preparing for exams like NEET, CSIR-NET, or USMLE or simply trying to understand this concept from your textbook—this guide covers everything you need, explained simply and clearly.
Let us start from the basics.
What is the Primary Structure of Proteins?
Before diving into the details, let us start with a clear, simple definition.
📌 Definition: The primary structure of a protein is the specific linear sequence of amino acids in a polypeptide chain, held together by covalent peptide bonds, and read directionally from the N-terminus (amino end, –NH₂) to the C-terminus (carboxyl end, –COOH).
Think of it like the letters in a word. Just as the specific order of letters determines the meaning of a word, the specific order of amino acids determines the identity and function of a protein. Change one letter — and the word (or protein) means something completely different.
Sequence is Unique to every protein
Every protein has its own distinct amino acid sequence, and no two different proteins share the exact same sequence. For example:
- Insulin (the blood sugar hormone) has a very specific sequence of 51 amino acids across two chains
- Hemoglobin (the oxygen carrier in red blood cells) has 141 amino acids in its alpha chain and 146 in its beta chain
- Collagen (the structural protein in skin and bones) has a repeating sequence of glycine–proline–hydroxyproline.
This uniqueness is not accidental — it is genetically programmed. Your DNA contains genes, and each gene carries the instructions (in the form of codons) to assemble a specific amino acid sequence. The process goes:
🧬 DNA → mRNA (Transcription) → Protein (Translation)
This means the primary structure of every protein is ultimately a direct reflection of the genetic code.
What Are the Components of Primary Structure?
The primary structure consists of three key elements:
1. Amino Acids: These are the individual “building blocks.” There are 20 standard amino acids, each with:
- An amino group (–NH₂)
- A carboxyl group (–COOH)
- A hydrogen atom (–H)
- A unique R group (side chain) — this is what makes each amino acid different
2. Peptide Bonds: Amino acids are linked together by peptide bonds — strong covalent bonds formed between the carboxyl group of one amino acid and the amino group of the next, with the release of a water molecule (condensation reaction).
3. Directionality (N→C): The polypeptide chain always has a defined direction:
- The N-terminus (free amino group, –NH₂) is the start of the chain
- The C-terminus (free carboxyl group, –COOH) is the end of the chain
By convention, amino acid sequences are always written and read left to right, from N-terminus to C-terminus.
How Long is a Primary Structure?
The length of a polypeptide chain varies widely between proteins:
| Protein | Function | Number of Amino Acids |
|---|---|---|
| Insulin (Chain A) | Blood glucose regulation | 21 |
| Insulin (Chain B) | Blood glucose regulation | 30 |
| Myoglobin | Oxygen storage in muscle | 153 |
| Hemoglobin (β-chain) | Oxygen transport in blood | 146 |
| Titin | Muscle elasticity | ~34,000 |
A chain of less than 50 amino acids is generally called a peptide or polypeptide. Chains longer than ~50 amino acids are typically referred to as proteins.
Primary Structure is the Foundation of All Protein Structure
Here is why primary structure is so critically important—it does not just describe a protein; it determines everything about that protein:
- The primary structure determines how the chain folds into secondary structures (alpha helices, beta sheets)
- The folding pattern determines the 3D shape (tertiary structure)
- The 3D shape determines the protein’s biological function
This is elegantly summarized by Anfinsen’s Dogma (Christian Anfinsen, Nobel Prize 1972):
“The primary structure of a protein contains all the information needed for it to fold into its correct three-dimensional structure.”
In other words, sequence is everything. Get the sequence right, and the protein folds correctly and does its job. Get it wrong, even by one amino acid, and the consequences can be severe — as we will see in the clinical examples later in this article.
How Peptide Bonds Form
Now that you understand what primary structure is, let us explore the chemistry behind it — specifically, how amino acids are joined together to build a polypeptide chain.
The answer lies in a special covalent bond called the peptide bond.
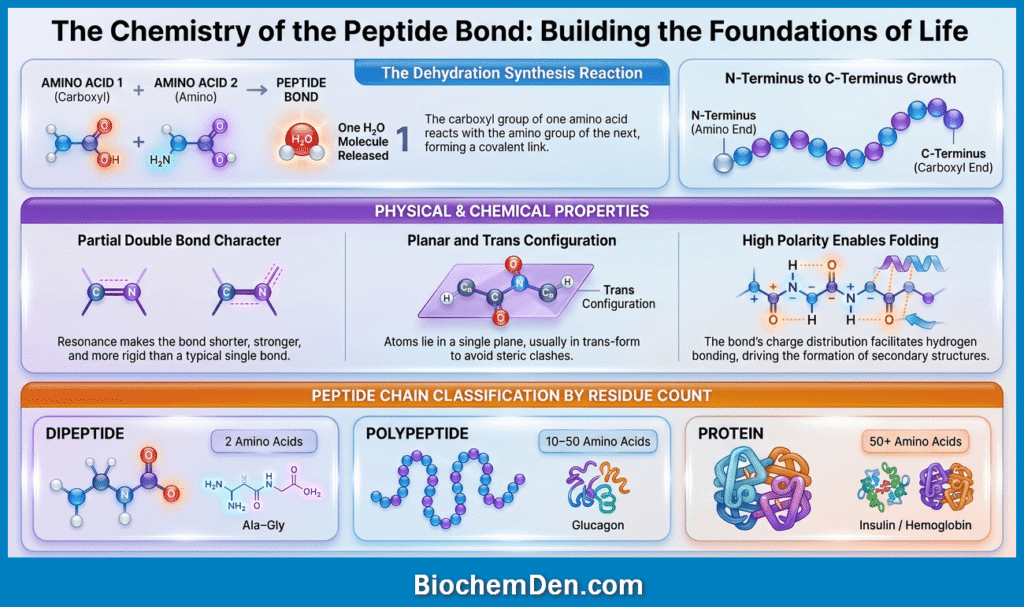
What is a Peptide Bond?
📌 Definition: A peptide bond is a covalent chemical bond formed between the carboxyl group (–COOH) of one amino acid and the amino group (–NH₂) of the next amino acid, with the release of one water molecule (H₂O).
Because a water molecule is released in the process, this reaction is called a condensation reaction (also known as a dehydration synthesis reaction).
The resulting bond—–CO–NH–—is the peptide bond, and it forms the backbone of every polypeptide chain.
Step-by-Step: How a Peptide Bond Forms
Here is the process broken down into simple steps:
- Two amino acids come together: the carboxyl group (–COOH) of Amino Acid 1 aligns with the amino group (–NH₂) of amino acid 2.
- A condensation reaction occurs: the –OH from the carboxyl group and the –H from the amino group combine
- Water is released: one molecule of H₂O is expelled as a byproduct
- A peptide bond (–CO–NH–) is formed: linking the two amino acids into a dipeptide
- The process repeats: each new amino acid is added to the C-terminus end, extending the chain one residue at a time
- A polypeptide chain: It grows directionally, always from N-terminus → C-terminus
🔬 In living cells, this process happens on the ribosome during translation, with the help of ribosomal RNA (rRNA) and transfer RNA (tRNA).
Naming Peptide Chains by Length
As amino acids are joined by peptide bonds, the resulting chains are named based on their length:
| Chain Length | Name | Example |
|---|---|---|
| 2 amino acids | Dipeptide | Ala–Gly |
| 3 amino acids | Tripeptide | Gly–Ala–Val |
| 2–10 amino acids | Oligopeptide | Oxytocin (9 AA) |
| 10–50 amino acids | Polypeptide | Glucagon (29 AA) |
| 50+ amino acids | Protein | Insulin, Hemoglobin |
Properties of the Peptide Bond
The peptide bond is not just a simple single bond—it has some unique and important chemical properties that students often overlook:
1. Partial Double Bond Character: The peptide bond has partial double bond character due to resonance between the carbonyl (C=O) and the nitrogen (N). This means:
- The bond is shorter and stronger than a typical C–N single bond
- It is rigid and planar—the four atoms (Cα–CO–NH–Cα) all lie in the same plane
2. Trans Configuration: In most peptide bonds, the two Cα atoms are on opposite sides of the bond (trans configuration). This minimizes steric clashes between R groups of adjacent amino acids.
3. Polarity: The peptide bond is polar — the C=O group is slightly negative (δ–) and the N–H group is slightly positive (δ+). This polarity allows peptide bonds to participate in hydrogen bonding, which drives secondary structure formation later.
4. It is a covalent bond: The peptide bond is a strong covalent bond. Breaking it requires either
- Acid or base hydrolysis (lab conditions)
- Proteolytic enzymes (proteases) — like trypsin, chymotrypsin, or pepsin in the body
The Polypeptide Backbone
When many amino acids are joined by peptide bonds, they form a polypeptide backbone—a repeating unit of
–[N–Cα–C]–[N–Cα–C]–[N–Cα–C]–
Where:
- N = nitrogen from the amino group
- Cα = the central alpha carbon (attached to the R group)
- C = the carbonyl carbon from the carboxyl group
The R groups (side chains) of each amino acid project outward from this backbone. These R groups are what give each amino acid its unique chemical identity, and they are what drive protein folding into higher-order structures.
💡 Quick Memory Tip for Students: “Carboxyl meets amino, water says goodbye—and a peptide bond is born!”
This simple phrase will help you remember:
- Which groups react (–COOH + –NH₂)
- What is released (H₂O)
- What is formed (peptide bond)
Key Takeaways — Peptide Bond Formation
| Feature | Detail |
|---|---|
| Reaction type | Condensation (Dehydration synthesis) |
| Bond formed | Peptide bond (–CO–NH–) |
| Byproduct | Water (H₂O) |
| Bond nature | Covalent, strong, rigid, planar |
| Direction of growth | N-terminus → C-terminus |
| Where it occurs in cells | Ribosome (during translation) |
| How it is broken | Hydrolysis (acid/base or proteases) |
Key Characteristics of Primary Structure
Now that you know what primary structure is and how peptide bonds form, let us look at the defining characteristics that make the primary structure of proteins unique. Understanding these features is essential for exams like NEET, CSIR-NET, and USMLE.
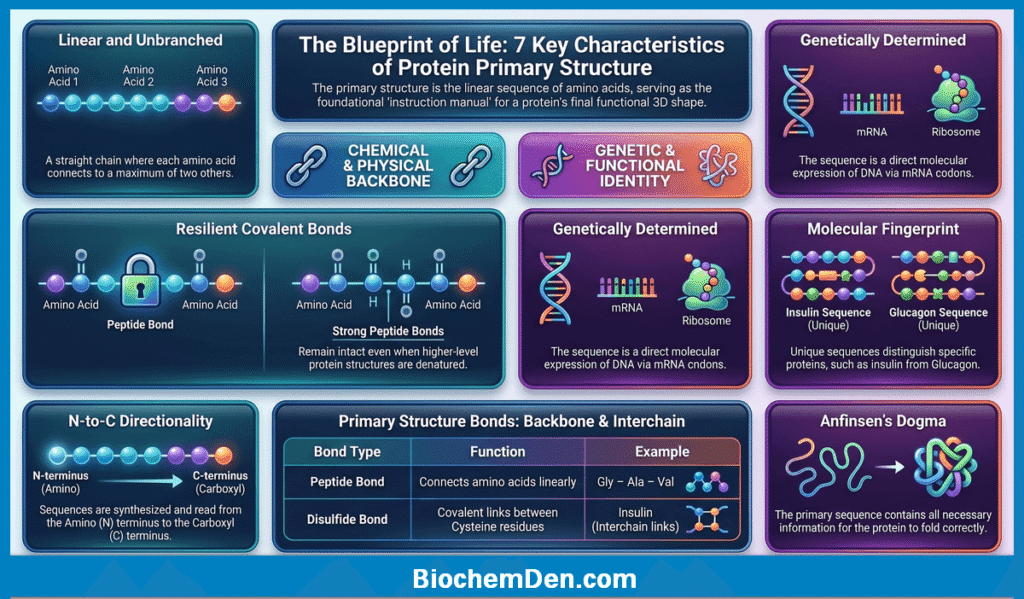
1. Linear and Unbranched
The primary structure of a protein is always a straight, unbranched chain of amino acids. Unlike carbohydrates (which can form branched chains), polypeptide chains do not branch—every amino acid is connected to a maximum of two other amino acids (one on each side via peptide bonds).
🔑 This linearity is what makes proteins predictable and sequenceable.
2. Held Together by Covalent Peptide Bonds
The amino acids in the primary structure are connected exclusively by covalent peptide bonds — the strongest type of chemical bond found in biological molecules.
This is important because
- Covalent bonds are not easily broken by temperature changes or mild pH shifts
- The primary structure remains intact even when the protein is denatured (unfolded)
- Denaturation disrupts secondary, tertiary, and quaternary structures—but the primary structure (peptide bonds) survives denaturation
📌 Key Exam Fact: Denaturation destroys protein function but does NOT break the primary structure. Only hydrolysis (by acid, base, or proteases) breaks peptide bonds.
3. Directionality (N-terminus → C-terminus)
Every polypeptide chain has a defined polarity—a beginning and an end:
- The N-terminus (amino terminus) carries a free —NH₂ group—this is the start of the chain
- The C-terminus (carboxyl terminus) carries a free –COOH group—this is the end of the chain
By convention, amino acid sequences are always written and read from left (N) to right (C). This directionality mirrors the direction of protein synthesis on the ribosome—ribosomes always build polypeptides from the N-terminus to the C-terminus.
Example:
Gly – Ala – Val – Leu – Phe (reading N → C)
This sequence is completely different from the following:
Phe – Leu – Val – Ala – Gly (reading N → C)
Even though it contains the same amino acids, it is a different protein with a different structure and function.
4. Unique Sequence
No two different proteins have the same amino acid sequence. The sequence of amino acids in a polypeptide is as unique as a fingerprint—it is what distinguishes
- Insulin from glucagon
- Hemoglobin from myoglobin
- Collagen from keratin
This uniqueness arises directly from the genetic code. Each gene encodes a specific sequence of amino acids, meaning the primary structure is a direct molecular expression of genetic information.
5. Genetically Determined
The primary structure of every protein is dictated by the nucleotide sequence of its gene. The central dogma of molecular biology explains this clearly:
🧬 DNA (gene) → mRNA (transcription) → Protein (translation)
- Every 3 nucleotides (codon) on the mRNA codes for one specific amino acid
- The ribosome reads the mRNA codons and adds the corresponding amino acids in order
- The result is a polypeptide chain with a precise, genetically encoded sequence
This is why mutations in DNA (even a single nucleotide change) can alter the primary structure and sometimes cause serious disease.
6. Higher Levels of Structure
Perhaps the most important characteristic of primary structure is that it contains all the information needed to fold into the correct 3D shape.
This was proven by Christian Anfinsen in his famous ribonuclease experiment (1950s):
- He denatured ribonuclease (unfolded it completely) using urea and mercaptoethanol
- He then removed the denaturing agents
- The protein spontaneously refolded into its original, functional shape
This proved that no external instructions are needed — the primary structure alone guides folding. This principle is known as Anfinsen’s dogma or the Thermodynamic Hypothesis.
📌 Anfinsen won the Nobel Prize in Chemistry in 1972 for this discovery.
7. Disulfide Bonds
While peptide bonds form the backbone of primary structure, some proteins also contain disulfide bonds (–S–S–) as part of their primary structure.
- Disulfide bonds form between the sulfhydryl groups (–SH) of two cysteine residues
- They are covalent bonds—strong and stable
- They can occur within the same chain (intrachain) or between two different chains (interchain)
Example: Insulin has three disulfide bonds—two interchain (connecting Chain A and Chain B) and one intrachain (within Chain A). These disulfide bonds are considered part of the primary structure because they are covalent.
Summary Table — Characteristics of Primary Structure
| Characteristic | Details |
|---|---|
| Chain type | Linear, unbranched polypeptide |
| Bond type | Covalent peptide bonds (–CO–NH–) |
| Directionality | N-terminus (–NH₂) → C-terminus (–COOH) |
| Uniqueness | Unique sequence for every protein |
| Genetic basis | Encoded by DNA via the genetic code |
| Stability | Survives denaturation; broken only by hydrolysis |
| Additional bonds | Disulfide bonds (between cysteine residues) |
| Role | Determines all higher-order structures and function |
💡 Quick Exam Tip for Students
“Primary structure = Peptide bonds only. Denaturation cannot break it. Only hydrolysis can.”
This single sentence answers at least 3–4 common exam MCQ traps about protein structure.
Role of Disulfide Bonds in Primary Structure
When we talk about the primary structure of proteins, most students immediately think of peptide bonds—and rightly so. But there is a second type of covalent bond that also plays a critical role in primary structure: the disulfide bond.
Understanding disulfide bonds is essential — they appear frequently in biochemistry exams and are clinically significant in many important proteins.
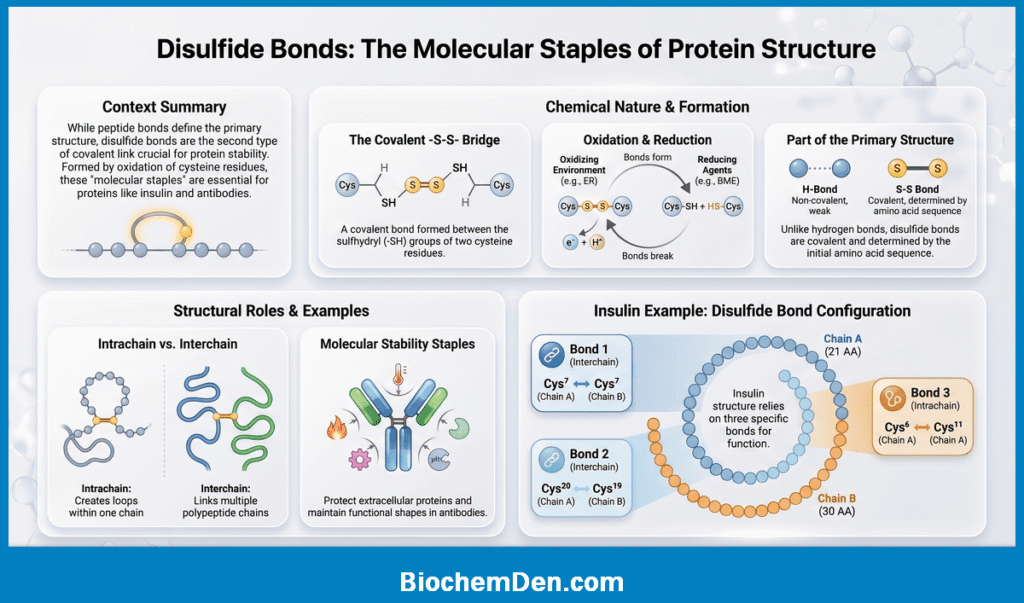
What is a Disulfide Bond?
📌 Definition: A disulfide bond (–S–S–) is a covalent bond formed between the sulfhydryl groups (–SH) of two cysteine amino acid residues through an oxidation reaction.
The reaction can be summarized as follows:
R–SH + HS–R → R–S–S–R + 2H⁺ + 2e⁻
In simpler terms:
- Two cysteine residues each contribute their –SH (thiol) group
- Oxidation removes two hydrogen atoms
- The two sulfur atoms bond together, forming a –S–S– (disulfide) bridge
🔑 Only the amino acid cysteine can form disulfide bonds, because it is the only standard amino acid with a free sulfhydryl (–SH) group in its R chain.
Where Do Disulfide Bonds Occur?
Disulfide bonds can form in two locations:
1. Intrachain Disulfide Bonds
- Form between two cysteine residues within the same polypeptide chain
- Create a loop or hairpin in the chain
- Example: Chain A of insulin has one intrachain disulfide bond (between Cys⁶ and Cys¹¹)
2. Interchain Disulfide Bonds
- Form between cysteine residues on two different polypeptide chains
- Hold multiple chains together
- Example: Insulin has two interchain disulfide bonds linking Chain A and Chain B
Disulfide Bonds in Insulin — A Classic Example
Insulin is the most studied and cited example of disulfide bonds in primary structure. Here is the complete picture:
| Disulfide Bond | Location | Type |
|---|---|---|
| Bond 1 | Cys⁷ (Chain A) — Cys⁷ (Chain B) | Interchain |
| Bond 2 | Cys²⁰ (Chain A) — Cys¹⁹ (Chain B) | Interchain |
| Bond 3 | Cys⁶ (Chain A) — Cys¹¹ (Chain A) | Intrachain |
🔬 These three disulfide bonds are essential for insulin’s biological activity. Breaking them destroys insulin’s ability to regulate blood glucose.
Frederick Sanger was the first scientist to determine the complete primary structure of insulin (including the positions of all three disulfide bonds) in 1955—a landmark achievement that earned him the Nobel Prize in Chemistry in 1958.
Are Disulfide Bonds Part of Primary Structure?
This is a common exam question—and the answer is yes.
Here is why:
- Disulfide bonds are covalent bonds—just like peptide bonds
- They directly connect specific amino acid residues in the polypeptide chain
- They are determined by the primary sequence (which cysteines are present and where)
- They do not require the protein to fold into a 3D shape to form (unlike hydrogen bonds in secondary structure)
📌 Key Exam Fact: Both peptide bonds AND disulfide bonds are covalent, and both are considered part of the primary structure. All non-covalent interactions (hydrogen bonds, ionic bonds, and hydrophobic interactions) belong to secondary, tertiary, or quaternary structure.
How Are Disulfide Bonds Formed and Broken?
Formation:
- Disulfide bonds form naturally in the oxidizing environment of the endoplasmic reticulum (ER) during protein folding
- The enzyme protein disulfide isomerase (PDI) catalyzes correct disulfide bond formation in the ER
- In the laboratory, oxidizing agents like molecular oxygen (O₂) or iodine can form disulfide bonds
Breaking:
- Disulfide bonds are broken by reducing agents such as:
- β-mercaptoethanol (BME) — commonly used in labs
- Dithiothreitol (DTT) — another common reducing agent
- Urea + reducing agents — used together to fully denature proteins (as in Anfinsen’s experiment)
🔬 This is why β-mercaptoethanol is added in SDS-PAGE (protein electrophoresis) — it breaks disulfide bonds to fully linearize the protein for accurate size separation.
Biological Importance of Disulfide Bonds
Disulfide bonds serve several critical functions in proteins:
1. Structural Stability
- They act as molecular staples, holding regions of the polypeptide chain together
- They make proteins more resistant to denaturation by heat or chemicals
- Proteins secreted outside the cell (extracellular proteins) tend to have more disulfide bonds because the extracellular environment is more oxidizing and harsh
2. Maintaining Functional Shape
- Many proteins require disulfide bonds to maintain the correct 3D shape needed for function
- Example: Antibodies (IgG) have multiple disulfide bonds connecting their heavy and light chains — disrupting these bonds destroys their ability to bind antigens
3. Directing Protein Folding
- During protein synthesis, the formation of correct disulfide bonds helps guide the protein into its proper tertiary structure
- Incorrect disulfide bond formation (mispairing of cysteines) leads to misfolded, non-functional proteins
Disulfide Bonds vs. Peptide Bonds — Quick Comparison
| Feature | Peptide Bond | Disulfide Bond |
|---|---|---|
| Atoms involved | C, O, N, H | S, S |
| Amino acid involved | All amino acids | Cysteine only |
| Type of reaction | Condensation | Oxidation |
| Location | Backbone of chain | Between R groups (side chains) |
| Function | Links amino acids in sequence | Stabilizes/cross-links chain(s) |
| Broken by | Hydrolysis (acid/base/proteases) | Reducing agents (BME, DTT) |
| Part of primary structure? | ✅ Yes | ✅ Yes |
💡 Quick Memory Tip for Students: Only cysteine can make disulfide bonds—because only cysteine carries a sulfur (–SH) group in its side chain. No Cysteine = No Disulfide Bond.”
Also remember the “3 disulfide bonds in insulin” rule—it is one of the most tested facts in biochemistry exams worldwide.
Real-Life Example — Insulin
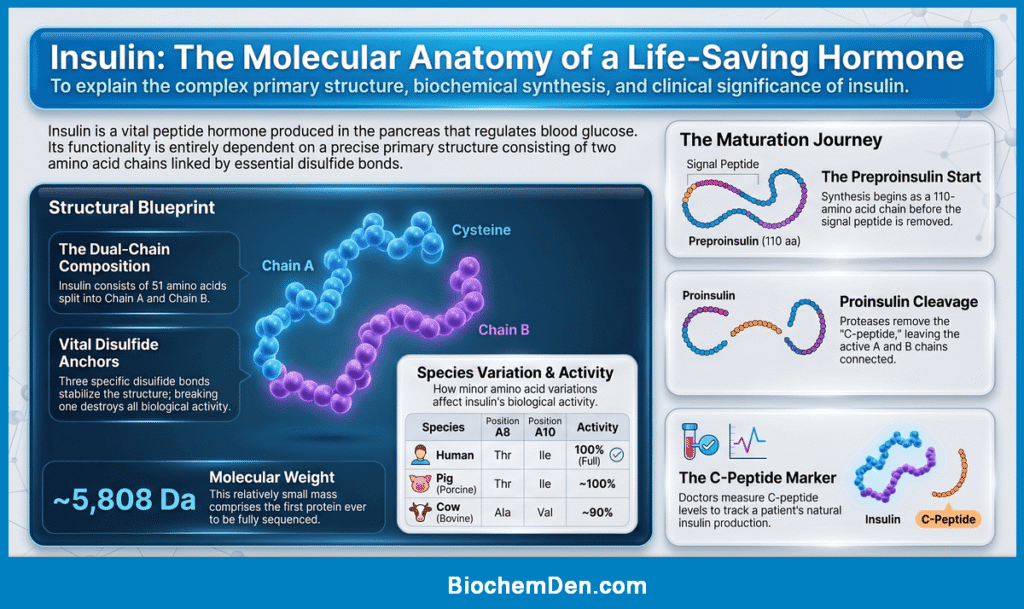
So far, you have learned about amino acids, peptide bonds, and the key characteristics of primary structure—all in theory. Now let us bring it all to life with the most famous and well-studied example of protein primary structure in all of biochemistry: Insulin.
Insulin is not just a textbook example — it is a life-saving hormone that millions of diabetic patients depend on every single day. And it all starts with its primary structure.
What is Insulin?
📌 Quick Facts:
- Type: Peptide hormone
- Produced by: Beta (β) cells of the Islets of Langerhans in the pancreas
- Function: Regulates blood glucose levels by promoting glucose uptake into cells
- Total amino acids: 51
- Molecular weight: ~5,808 Da
- Number of chains: 2 (Chain A and Chain B)
- Disulfide bonds: 3 (two interchain, one intrachain)
The Primary Structure of Insulin
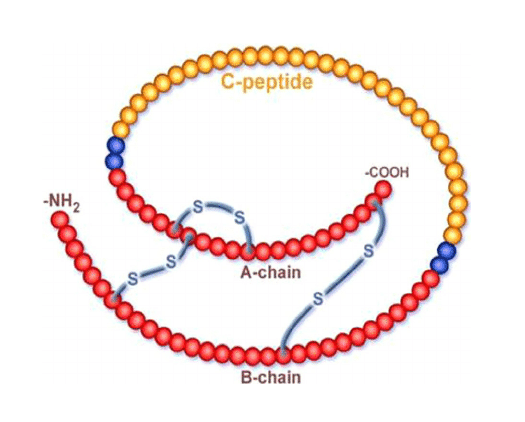
Insulin is unique because it consists of two polypeptide chains—Chain A and Chain B—that are held together by disulfide bonds as part of its primary structure.
Chain A:
- Contains 21 amino acids
- Has one intrachain disulfide bond (between Cys⁶ and Cys¹¹)
- N-terminus starts with Glycine (Gly)
- C-terminus ends with Asparagine (Asn)
Gly–Ile–Val–Glu–Gln–Cys–Cys–Thr–Ser–Ile–Cys–Ser–Leu–Tyr–Gln–Leu–Glu–Asn–Tyr–Cys–Asn
Chain B:
- Contains 30 amino acids
- N-terminus starts with Phenylalanine (Phe)
- C-terminus ends with Threonine (Thr)
Phe–Val–Asn–Gln–His–Leu–Cys–Gly–Ser–His–Leu–Val–Glu–Ala–Leu–Tyr–Leu–Val–Cys–Gly–Glu–Arg–Gly–Phe–Phe–Tyr–Thr–Pro–Lys–Thr
The Three Disulfide Bonds of Insulin
The two chains are connected and stabilized by three disulfide bonds:
| Disulfide Bond | Chain A Position | Chain B Position | Type |
|---|---|---|---|
| Bond 1 | Cys⁷ (A7) | Cys⁷ (B7) | Interchain |
| Bond 2 | Cys²⁰ (A20) | Cys¹⁹ (B19) | Interchain |
| Bond 3 | Cys⁶ (A6) | Cys¹¹ (A11) | Intrachain |
🔬 These three disulfide bonds are absolutely essential — breaking any one of them destroys insulin’s biological activity completely.
How Insulin is Originally Made (The Preproinsulin Story)
Here is something fascinating that students often do not know — mature insulin is not the original form synthesized by the cell. It goes through a remarkable processing journey:
Step 1: Preproinsulin
- The gene encodes a single chain of 110 amino acids called preproinsulin
- It includes a signal peptide (24 amino acids) at the N-terminus that directs the protein to the endoplasmic reticulum
Step 2: Proinsulin
- The signal peptide is cleaved in the ER
- The remaining 86 amino acid chain is called proinsulin
- Proinsulin is a single chain: B chain – C peptide – A chain
- Disulfide bonds form correctly in the ER
Step 3: Mature Insulin
- In the Golgi apparatus and secretory granules, the C peptide (31 amino acids) is cleaved out by proteases (proinsulin convertase 1, 2 and carboxypeptidase E)
- The result is mature two-chain insulin (Chain A + Chain B) connected by two interchain disulfide bonds
📌 Clinical Note: C peptide levels in blood are used clinically to measure the body’s own insulin production. In type 1 diabetes, C-peptide is absent or very low.
Why Insulin’s Primary Structure Matters — Species Comparison
One of the most powerful demonstrations of how primary structure determines function is seen when we compare insulin across species:
| Species | Position A8 | Position A9 | Position A10 | Biological Activity |
|---|---|---|---|---|
| Human | Thr | Ser | Ile | ✅ Full activity |
| Pig (Porcine) | Thr | Ser | Ile | ✅ ~100% (used clinically) |
| Cow (Bovine) | Ala | Ser | Val | ✅ ~90% activity |
| Dog | Thr | Ser | Ile | ✅ Similar to human |
🔑 Notice that porcine (pig) insulin differs from human insulin by only 1 amino acid at position B30 (Ala instead of Thr) — yet it is biologically active enough to have been used to treat human diabetic patients for decades before recombinant human insulin was developed.
This beautifully illustrates how even minor changes in primary structure can subtly affect protein function—and how conservation of key sequences across species reflects evolutionary and functional importance.
Who Discovered Insulin’s Primary Structure?
🏆 Frederick Sanger — British biochemist
- Determined the complete amino acid sequence of insulin between 1949 and 1955
- Used a technique called partial acid hydrolysis combined with paper chromatography
- This was the first time any protein’s complete primary structure was determined
- Awarded the Nobel Prize in Chemistry in 1958 for this achievement
- Sanger later won a second Nobel Prize in Chemistry in 1980 for DNA sequencing—making him one of only four people to win two Nobel Prizes
📌 Exam Fact: Frederick Sanger is the only person to win the Nobel Prize in Chemistry TWICE. His work on insulin established that proteins have a definite, fixed amino acid sequence—which was not known before his work.
Key Takeaways — Insulin as Primary Structure Example
| Feature | Detail |
|---|---|
| Number of chains | 2 (Chain A: 21 AA, Chain B: 30 AA) |
| Total amino acids | 51 |
| Disulfide bonds | 3 (two interchain, one intrachain) |
| Original precursor | Preproinsulin (110 AA) → Proinsulin (86 AA) → Insulin (51 AA) |
| Discovered by | Frederick Sanger (1955) |
| Nobel Prize | 1958 (Chemistry) |
| Clinical relevance | Treatment of Type 1 & Type 2 diabetes |
| Species comparison | Pig insulin differs by only 1 AA from human insulin |
💡 Quick Memory Tip for Students: “Insulin = 51 AA, 2 chains (A=21, B=30), 3 disulfide bonds, discovered by Sanger (Nobel 1958).”
Why is the primary structure important?
The primary structure of a protein is important because it determines the protein’s final shape, stability, and function. In simple terms, the amino acid sequence is the blueprint that controls everything the protein does.
A protein is only as good as its sequence. Even a single amino acid change can alter how the protein folds, how it interacts with other molecules, and whether it works properly at all. This is why the primary structure is often called the foundation of protein structure.
- Protein Folding: The sequence of amino acids influences how a protein folds into secondary and tertiary structures. Specific amino acids favor specific shapes, so the order of amino acids strongly affects whether the protein forms an alpha helix, beta sheet, or a more complex 3D structure. If the sequence changes, the folding pattern can also change. That means the protein may not reach its correct shape, and without the correct shape, it may not function properly.
- Biological Function: Proteins work because of their shape. Enzymes bind substrates, receptors bind signals, and transport proteins carry molecules because their structure fits their job. Since the primary structure controls folding, it indirectly controls function. For example, hemoglobin can carry oxygen only because its amino acid sequence allows it to fold into the correct shape. If that sequence is altered, oxygen transport can be affected.
- Small Changes Can Cause Disease: A tiny change in the primary structure can have major effects. One classic example is sickle cell anemia, where a single amino acid substitution in the beta chain of hemoglobin changes the behavior of the protein and leads to serious medical problems. This shows why the exact amino acid order matters so much. A protein is not just a chain of amino acids; it is a precisely coded biological molecule.
- Evolutionary Relationships: Proteins with similar primary structures often come from related genes and may have similar functions. Scientists compare protein sequences across species to study evolution and trace relationships between organisms. The more similar the sequence, the more closely related the proteins are likely to be. This is why primary structure is useful not only in biology and medicine but also in evolutionary studies.
- Protein Engineering and Drug Design: Understanding primary structure helps scientists design better medicines, enzymes, and therapeutic proteins. When researchers know the sequence, they can predict how a protein may behave and how a mutation might affect its activity. This is especially important in biotechnology, where even one sequence change can improve stability, reduce side effects, or change function in a useful way.
Quick Summary Table
| Importance | What it means |
|---|---|
| Folding | The sequence guides how the protein folds |
| Function | Shape determines what the protein can do |
| Disease | Sequence changes can cause disorders |
| Evolution | Sequence similarity shows relatedness |
| Biotechnology | Helps in protein design and drug development |
Simple Exam Line: Primary structure is important because it determines the higher levels of protein structure and, ultimately, the protein’s function.
How is the Primary Structure Determined?
Scientists determine the primary structure of a protein by identifying the exact order of amino acids in the polypeptide chain. This can be done directly by protein sequencing methods or indirectly by reading the gene that encodes the protein.
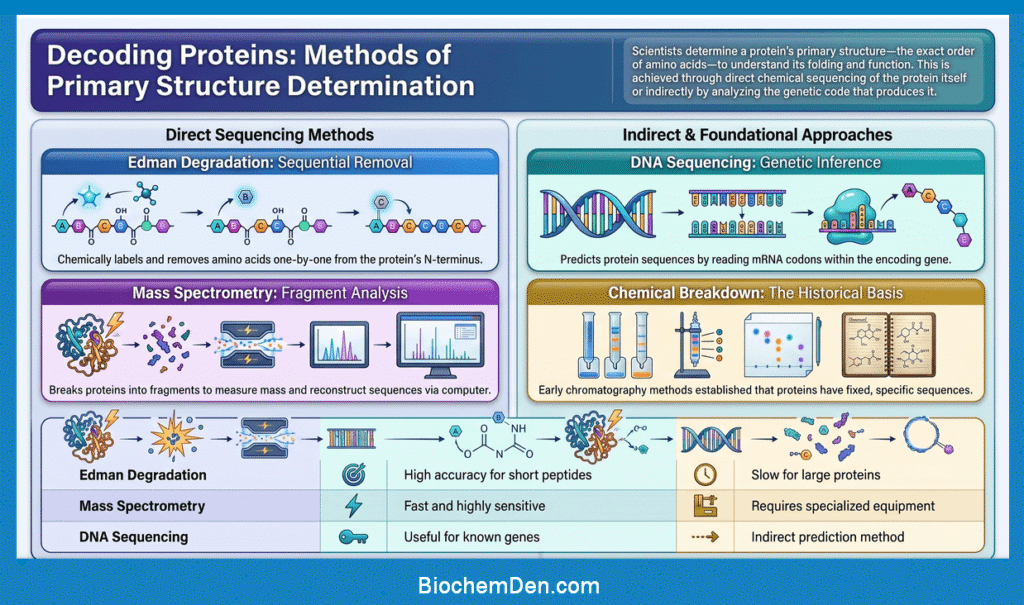
1. Edman Degradation
Edman degradation is a classic method used to determine the amino acid sequence from the N-terminus of a protein.
- The first amino acid is labeled and removed
- It is identified chemically
- The process is repeated step by step
- This allows the sequence to be read one amino acid at a time
This method works best for short peptides and purified proteins. It is very accurate, but it is slow for large proteins.
2. Mass Spectrometry
Mass spectrometry is a modern and powerful method for protein sequencing.
- The protein is broken into smaller peptide fragments
- The masses of the fragments are measured
- Computers help reconstruct the amino acid sequence
- It is fast and sensitive and can analyze very small amounts of protein
This is one of the most important tools used in modern biochemistry and proteomics.
3. DNA Sequencing
Sometimes scientists determine the primary structure indirectly by sequencing the gene that codes for the protein.
- DNA is sequenced first
- The mRNA codons are inferred
- The amino acid sequence is predicted from the genetic code
This method is useful because every codon corresponds to a specific amino acid, so the protein sequence can often be predicted from the gene sequence.
4. Historical Method: Protein Breakdown and Chromatography
Before modern techniques were developed, scientists used chemical breakdown methods and chromatography to identify amino acids in a protein. This approach was used in the landmark work on insulin sequencing.
Although older, this method helped establish the basic idea that proteins have a fixed and specific sequence.
| Method | Main idea | Advantage | Limitation |
|---|---|---|---|
| Edman degradation | Removes amino acids one by one from the N-terminus | Accurate for short peptides | Slow for large proteins |
| Mass spectrometry | Measures peptide fragment masses | Fast and highly sensitive | Needs specialized equipment |
| DNA sequencing | Predicts protein sequence from gene sequence | Useful for known genes | Indirect method |
| Chemical breakdown | Identifies amino acids after hydrolysis | Historical importance | Less precise than modern methods |
Why This Matters
Knowing the primary structure is important because it helps scientists understand how a protein works, how it folds, and how mutations may affect it. It is also essential in medicine, biotechnology, and drug discovery.
Simple Exam Line: The primary structure of a protein can be determined by direct sequencing of the protein or indirectly by sequencing the gene that encodes it.
Primary vs Secondary vs Tertiary vs Quaternary Structure
Protein structure is described in four levels, and each level builds on the one before it. Understanding the difference between them helps students see how a simple amino acid sequence becomes a functional protein.
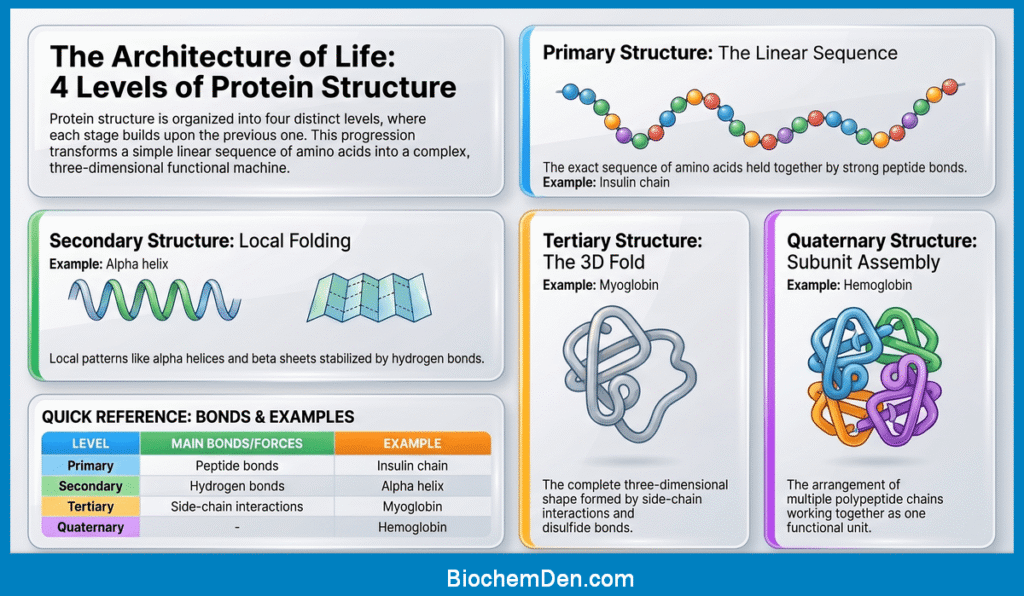
- Primary Structure: The primary structure is the exact linear sequence of amino acids in a protein. It is held together by peptide bonds and is written from the N-terminus to the C-terminus. This sequence is unique for every protein and determines all later levels of structure.
- Secondary Structure: The secondary structure refers to local folding patterns in the polypeptide chain. The two most common forms are the alpha helix and beta sheet. These structures are stabilized mainly by hydrogen bonds between backbone atoms.
- Tertiary Structure: The tertiary structure is the complete 3D shape of a single polypeptide chain. It is formed by interactions between side chains, including hydrophobic interactions, ionic bonds, hydrogen bonds, and disulfide bonds. This level gives the protein its final functional shape.
- Quaternary Structure: The quaternary structure is found in proteins made of more than one polypeptide chain. It describes how multiple subunits fit together to form one functional protein. Hemoglobin is a classic example.
Comparison Table
| Level | Definition | Main Bonds/Forces | Example |
|---|---|---|---|
| Primary | Amino acid sequence | Peptide bonds | Insulin chain |
| Secondary | Local folding | Hydrogen bonds | Alpha helix |
| Tertiary | 3D shape of one chain | Hydrophobic, ionic, H-bonds, disulfide | Myoglobin |
| Quaternary | Arrangement of multiple chains | Same as tertiary plus subunit interactions | Hemoglobin |
Easy Way to Remember
Think of it like building a house:
- Primary = the bricks in order
- Secondary = small wall patterns
- Tertiary = the full house shape
- Quaternary = several house units joined together
Simple Exam Line: Primary structure is the amino acid sequence, secondary structure is local folding, tertiary structure is the full 3D shape, and quaternary structure is the arrangement of multiple chains.
Clinical Significance and Examples
The primary structure of proteins is not just a textbook concept; it has direct medical importance. A small change in amino acid sequence can lead to altered protein function and disease.
- Sickle Cell Anemia: The classic example is sickle cell anemia. In this disorder, a single amino acid substitution in the beta chain of hemoglobin changes the protein’s behavior. This one change causes red blood cells to become stiff and sickle-shaped, which can block blood flow and reduce oxygen delivery.
- Phenylketonuria: Another important example is phenylketonuria (PKU). PKU happens when a mutation affects the enzyme phenylalanine hydroxylase. Because the protein sequence is altered, the enzyme does not work properly, and phenylalanine builds up in the body. If untreated, this can damage the brain.
- Insulin and Diabetes: Insulin is also a strong example of why primary structure matters. Its exact amino acid sequence and disulfide bond pattern are necessary for proper activity. If the sequence is changed, insulin may lose function or become less effective in controlling blood glucose.
Why It Matters in Medicine
Doctors and scientists study primary structure to understand the following:
- Genetic disorders caused by mutations
- How proteins misfold
- How drugs interact with proteins
- How to design therapeutic proteins
Quick Example Table
| Condition | Protein affected | What changes |
|---|---|---|
| Sickle cell anemia | Hemoglobin | Single amino acid substitution |
| PKU | Phenylalanine hydroxylase | Enzyme function is reduced |
| Diabetes | Insulin | Sequence or structure affects activity |
Simple Exam Line: Changes in the primary structure of a protein can alter its function and may cause disease.
Frequently Asked Questions (FAQs)
What is the primary structure of a protein?
The primary structure of a protein is the exact linear sequence of amino acids in a polypeptide chain. The amino acids are linked by peptide bonds and are read from the N-terminus to the C-terminus.
What bonds maintain the primary structure of proteins?
Primary structure is maintained mainly by peptide bonds, which are covalent bonds. In some proteins, disulfide bonds are also considered part of the primary structure because they are covalent links between cysteine residues.
Why is the primary structure important?
The primary structure is important because it determines how the protein folds and functions. Even one amino acid change can affect the protein’s shape and may cause disease.
What is the difference between primary and secondary structure?
Primary structure is the amino acid sequence, while secondary structure is the local folding of the chain into alpha helices and beta sheets. Secondary structure is stabilized mostly by hydrogen bonds.
What is an example of primary structure of a protein?
A well-known example is insulin, which has a specific amino acid sequence in its A and B chains. Another common example is hemoglobin, where even one amino acid change can cause sickle cell anemia.
Can a protein function if its primary structure changes?
Sometimes a protein may still function partially, but often a change in primary structure can reduce or completely destroy its activity. The effect depends on the location and nature of the amino acid change.
Who first determined the primary structure of a protein?
Frederick Sanger was the first scientist to determine the complete primary structure of a protein, insulin. His work showed that proteins have a definite amino acid sequence.
Final words on Primary Structure of Proteins
The primary structure of proteins is the amino acid sequence that forms the foundation of every protein’s shape and function. If students understand this first level clearly, the rest of protein structure becomes much easier to learn.
In this article, we covered what primary structure is, how peptide bonds form, why disulfide bonds matter, how insulin demonstrates the concept in real life, and how small sequence changes can lead to disease. We also compared primary structure with the other levels of protein structure and answered the most common exam-style questions.
A strong conclusion for students should end with one clear idea: sequence determines structure, and structure determines function. That single principle is the key to understanding proteins in biochemistry.
Discover more from Biochemistry Den
Subscribe to get the latest posts sent to your email.